O Database Snaphot (ou “instantâneo de Banco de Dados”, se você estiver no SQL Server em português – Que nome terrível, hehehe) é um banco de dados _somente leitura, _onde o SQL Server guarda os dados originais de tudo o que está sendo alterado pelos usuários, para que seja possível realizar verificações (dentre outras coisas) de como estava o banco antes destas ocorrerem.
Ao contrário do que muita gente pensa, as alterações ocorrem nas páginas de dados e não no objeto que está sofrendo alteração. O SQL Server utiliza um recurso chamado “Copy-on-write” onde, antes da página ser alterada, os dados originais são armazenados no snapshot.
A minha ideia incial era tentar mostrar dentro das páginas de dados quando estaríamos acessando o banco original (consultando o snapshot) e quando estaríamos vendo os dados alterados e enviados para o snapshot, porém em conversa com o grande Luciano Moreira (twitter | blog), ele me falou que isso não era possível (após um papo com o Paul Randal… Loucura esse mundo, ehehe), que cada página fica em um mapa de bits na memória e que para buscar isso apenas usando um debugger no SQL Server… Aí já viu né… Ficamos assim, hehehehe
Abaixo, tentarei demonstrar o funcionamento do snapshot… Mas vou tentar fazer algo diferente: ao invés de jogar todo o script, vou colocar ele por blocos e, no final, disponibilizo o script para download. Depois me digam o que acharam.
Primeiro, vamos criar a base e inserir alguns dados…
/*
Criando o banco, a tabela e inserindo alguns registros...
*/
CREATE DATABASE DatabaseSnapshot
CREATE DATABASE Origem
ON (NAME ='Origem_Data',
FILENAME = N'D:\Bases\DatabaseSnapshot\Origem_Data.mdf')
LOG
ON (NAME = 'Origem_Log',
FILENAME = N'D:\Bases\DatabaseSnapshot\Origem_Log.ldf')
GO
USE Origem
CREATE TABLE Pessoa (Codigo int identity(1,1), Nome char(2000), nascimento date)
GO
INSERT INTO Pessoa
VALUES ('Logan', '1981-05-25'), ('Kratos', '1980-05-25'),
('Cronos', '1979-05-25'), ('Brucilí', '1980-07-25'),
('Fulano', '1980-07-25')Vejam que eu criei a coluna Nome como char(2000), apenas para que alguns registros estejam em cada página de dados (entenda o que é uma página de dados aqui).
Feito isso, vamos criar um snapshot:
/* Criação do Snapshot do Banco Origem */ CREATE DATABASE DatabaseSnapshot ON (name = DBSS_Data , FILENAME = 'D:\Bases\DatabaseSnapshot\DBSS_Data.ss') AS SNAPSHOT OF Origem
Notem a sintaxe da criação do snapshot… Ela é muito semelhante com a de criação de um banco comum, com exceção do Log (que não existe no snapshot) e a informação do banco de origem (AS SNAPSHOT OF …). E aos que estão querendo saber como fazer pelo SSMS, eu sinto muito, mas não é possível. Tem que ser na munheca mesmo (e nem é tão complicado assim, vai).
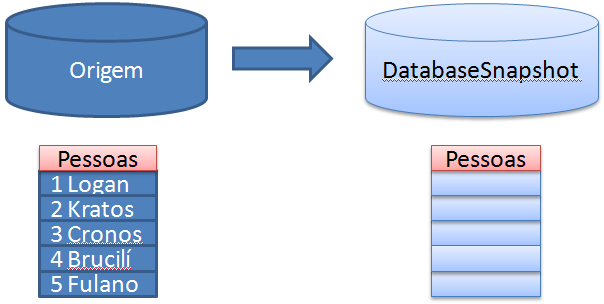
Com isso, a nossa estrutura ficou assim, até o momento:
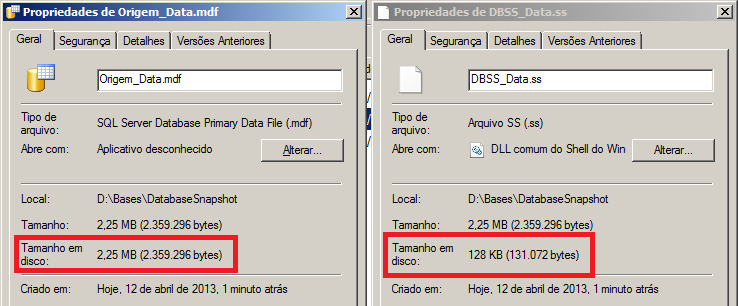
Dando uma olhada nas propriedades do .ss que foi criado dá pra ver que o arquivo está praticamente vazio, apesar de uma consulta no banco trazer os dados normalmente (faça um select para confirmar). Isso ocorre pois o snapshot trabalha com o conceito de Sparse Files. Veja a imagem abaixo:
Agora, vamos alterar um registro, apagar outro e inserir um novo e, então, vamos comparar com o snapshot para ver o resultado:
/*
Alteração de alguns dados na base de origem
*/
UPDATE Pessoa
SET nome = 'Logan Merazzi', nascimento = '2013-04-10'
WHERE Codigo = 1
DELETE FROM Pessoa WHERE Codigo = 5
INSERT INTO Pessoa VALUES ('Waldisnei','1985-05-30')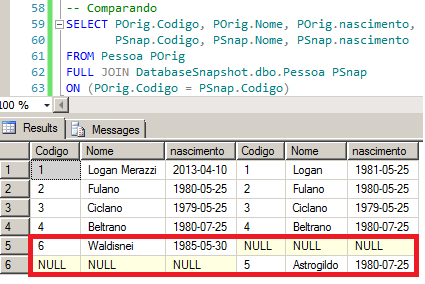
Viram os valores originais no snapshot?
Com isso, a estrutura passou para a seguinte situação:
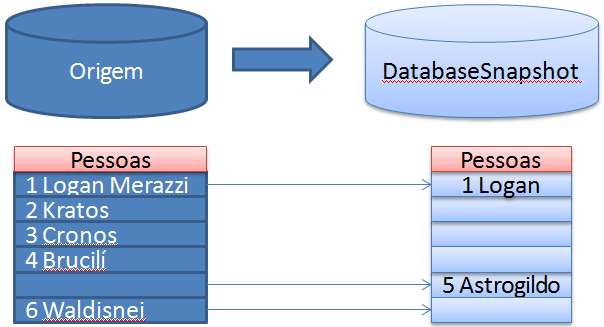
É possível realizar a criação de “N” snapshots, um para cada momento desejado.
Vamos criar um novo snapshot, fazer algumas alterações, comparar o resultados novamente e então partir pra exclusão e restauração…
/*
Criação de um Segundo Snapshot, para podermos consultar os estados...
*/
CREATE DATABASE DatabaseSnapshot_V2
ON
(name = Data , FILENAME = 'D:\Bases\DatabaseSnapshot\DBSSV2_Data.ss')
AS
SNAPSHOT OF Origem
GO
update Pessoa
set nome = RTRIM(Nome) + ' A', nascimento = '2020-10-10'
where Codigo in (3,6)
-- Comparando
SELECT POrig.Codigo, POrig.Nome, POrig.nascimento,
PSnap.Codigo, PSnap.Nome, PSnap.nascimento,
PSnap2.Codigo, PSnap2.Nome, PSnap2.nascimento
FROM Pessoa POrig
FULL JOIN DatabaseSnapshot.dbo.Pessoa PSnap
ON (POrig.Codigo = PSnap.Codigo)
FULL JOIN DatabaseSnapshot_V2.dbo.Pessoa PSnap2
ON (POrig.Codigo = PSnap2.Codigo)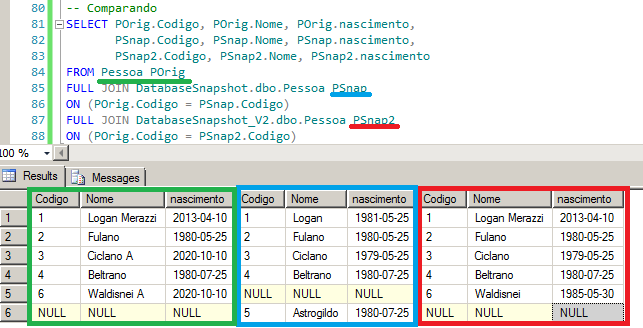
A sintaxe para restaurar um snapshot é a seguinte:
RESTORE DATABASE DatabaseSnapshot FROM DATABASE_SNAPSHOT = 'DatabaseSnapshot';
Porém é importante frisar que para a restauração funcionar, deve existir apenas um snapshot associado, desta forma, todos os demais snapshots devem ser excluídos.
/* Vamos restaurar o snapshot para a posição original... */ use master RESTORE DATABASE Origem FROM DATABASE_SNAPSHOT = 'DatabaseSnapshot'; -- Erro? -- Precisamos dropar os demais snapshots... DROP DATABASE DatabaseSnapshot_V2 -- E agora? Vai? RESTORE DATABASE Origem FROM DATABASE_SNAPSHOT = 'DatabaseSnapshot'; select * from DatabaseSnapshot.dbo.Pessoa select * from Origem.dbo.Pessoa
Com a base restaurada a partir do snapshot, vejam que a base voltou para o mesmo estado do início do post.
Considerações:
- Snapshot não substitui backup. Ele ajuda para restaurações pontuais, porém como o snapshot é diretamente dependente da base original (você não consegue apagar o banco ou restaurá-lo se houver um snapshot associado), qualquer erro que ocorra na base original (base corrompida, falha no disco, etc), os dados não estarão mais seguros.
- Para criação de bases de testes, homologação e demonstração é uma mão na roda… voltar uma base de um snapshot, dependendo do tamanho da base, é muito mais rápido. Sem contar que as comparações das alterações se tornam muito mais simples de serem verificadas.
- Esse recurso está disponível a partir da versão 2005 do SQL Server, porém apenas na edição Enterprise (ou Developer).
- A complexidade de administração aumenta um pouco, pois você tem que prestar muita atenção quando houverem vários snapshots criados para saber qual ponto restaurar e avaliar a perda do “histórico”.
- Você terá um aumento considerável de I/O de disco… então use-o com sabedoria.
Bom, fico por aqui… Façam as suas considerações e vamos discutindo.
O script completo está aqui. Enjoy!
[]’s!